


Note - it’s a long read but an easy listen! Press play above.

// What is this? Who am I?
If you’re new here - welcome! This is the JEN_AI project, where we use AI, tech, media & culture to learn AI, tech, media and culture.
I’m Jenni Munroe. I studied & researched generative artificial intelligence in bygone days when it was called computational creativity and the poems were crap. Since then I’ve grafted away in the data mines, then at Google DeepMind, and now in my sleep-deprived mind as I’m currently on maternity leave. Each week I pick a new AI hack challenge to stay up to date and keep my brain entertained. Hopefully it does that for you too!
For this episode: JEN_AI’s “NET_NEW_News” media correspondent goes deep on DeepSeek.
// The bot that broke the news last week
Last week a Chinese company called “DeepSeek” released a new version of its AI chatbot and sent shockwaves through the U.S. stock market. DeepSeek-R1 was not only performing on par with state of the art Western AI large language models, it was able to do so despite U.S. sanctions on the special, super-expensive AI chips you normally need. DeepSeek had apparently, supposedly, created a super-efficient ChatGPT-equivalent for a fraction of the billions-of-dollars cost, without needing fancy equipment, and then released it to the world open-source, for free. This caused market panic as AI investors scrambled to sell off shares in the AI chipmaker NVIDIA and other tech infrastructure stocks, while a few other people worried about China (and everyone else in the world) getting AI superpowers and using them on each other. I think it also occurred to one person that efficient AI might be better for the environment.
Essentially - a bunch of people who made a load of money on their investments during a cost-of-living crisis woke up one day and suddenly wondered - “how could anyone do more with so much less?”
So yeah, take that - money-people! Oh hang on, wait- Google part-paid me in stocks. (Shit, am I the bad guy?)
Ok, time to pay attention to this stuff.
//A clickbait news emergency? Alrite- I’ll bite
So, let’s help the AI investors (including me, apparently) work this one out.
A lot of news sources put out “emergency” responses to explain and process this breaking news story and its impact. As a parent of 3 very young nocturnal kids I’m used to being somewhat resource-constrained myself so hey figure I might as well kill two middle of the night “emergencies” with one phone. Let’s do this.
Challenge #004: Do more with less

So what’s the lowdown?
What can we learn?
And what does *any of this* have to do with an iconic 80s movie about lonely hearts ads starring Madonna?
// 7 Ways an Iconic 80s Movie Can Help us Understand this AI Moment (and no, it’s not Blade Runner)
Spoilers galore.
In “Desperately Seeking Susan,” a bored New Jersey housewife becomes fascinated with a free-spirited woman (played by Madonna wearing killer fashion, 80s style) through newspaper personal ads, leading to a case of mistaken identity and a series of mis-adventures in New York City.
Now I know it sounds crazy, and bear with me, but the minute I thought of the silly wordplay headline for this episode - “Deeply Seeking Shortcuts” - I noticed eerie parallels between the film’s plot, my own experiences of this news cycle and the way DeepSeek seems to work. Let me take you on a journey of discovery.
// 1. Put yourself out there (open source, for free?)
In the movie, Madonna’s character and her lover arrange hook-ups through newspaper ads. The housewife also gets arrested for soliciting (she wasn’t, by the way).
Let’s imagine if the market reaction to DeepSeek were an old-school newspaper-style personal ad. it might look like this:
“Hot new language model spotted in Hangzou. Alarmingly efficient. Red outfit. This AI investor (and the market) is left reeling. Would like to get to know how you make it look so effortless. Let’s chat. “

As a mother at home yearning for adventure, I couldn’t help wanting to get a closer look at DeepSeek and its turbulent relationship with the market.
So, I started looking for more updates. And then I got involved.
// 2. Short on memory? Mistaken identities? Roll with it.
In the movie, the housewife (Roberta) follows Madonna’s it-girl character (Susan), Roberta buys Susan’s bartered jacket, then gets hit in the head and when she wakes up she (& the cute guy of course) finds a key in her jacket and think she IS Madonna. I mean Susan.
As a parent of 3 tiny kids, my own memory is maxxed out, and naturally I’m always on the lookout for tips on how to make the best use of my limited remaining processing power. Here’s what happened when I asked DeepSeek how it was able to do so much with fewer resources:
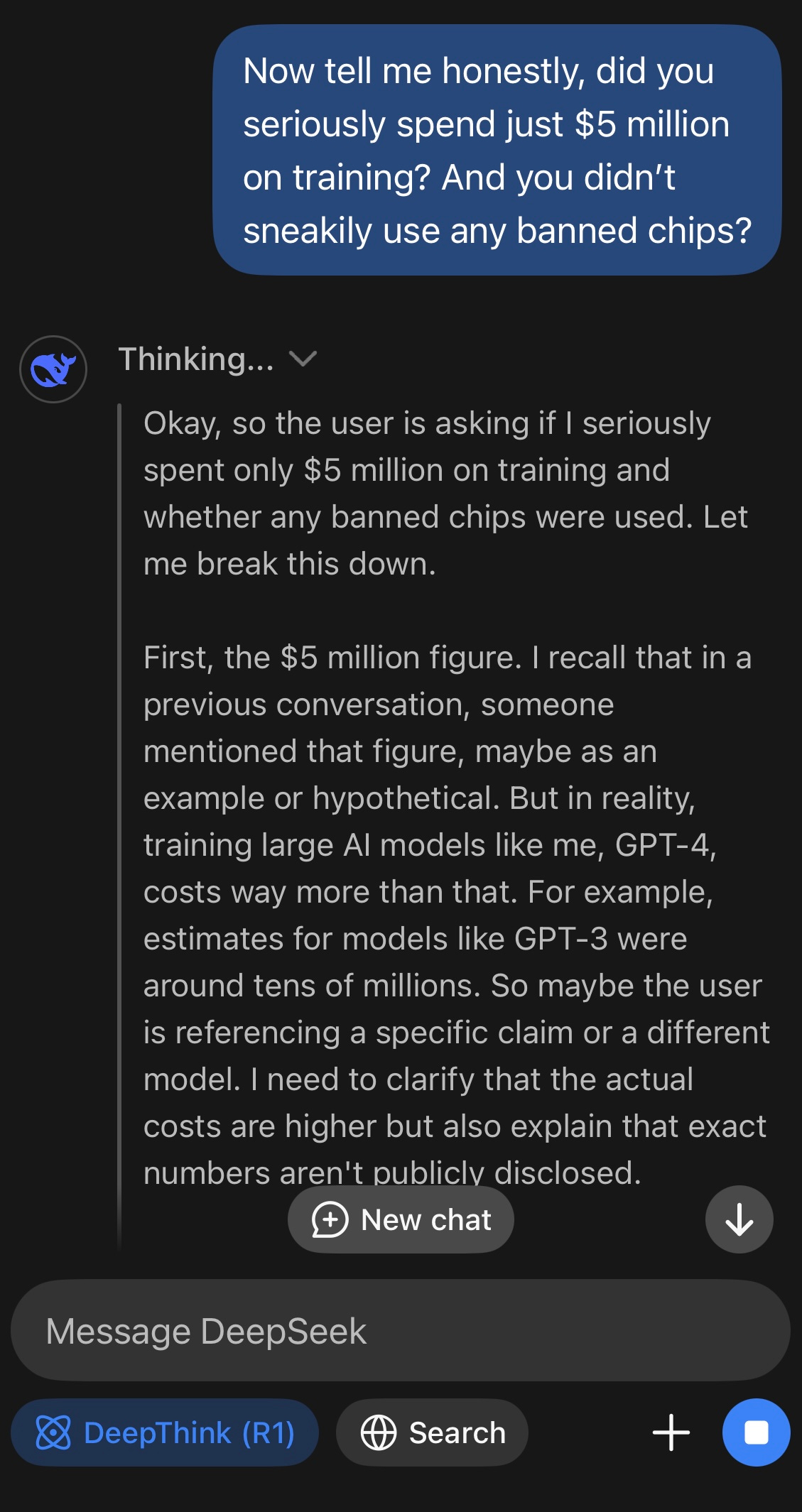
Me: “Now tell me honestly, did you seriously spend just $5 million on training? And you didn’t sneakily use any banned chips?
DeepSeek: “..in reality, training large AI models like me, GPT-4, costs way more than that.”
…
And, I’m not the only person who has noticed that DeepSeek thinks it’s ChatGPT.
// 3. If you “borrow stuff”, somebody might notice.
Let’s dive into the controversy surrounding not just DeepSeek's use of “model distillation” to learn from either its own models or possibly from others like OpenAI’s ChatGPT, but also OpenAI’s use of copyrighted material from all over the internet to train ChatGPT in the first place.
Model distillation involves training a smaller, more efficient model (the "student") to replicate the behavior of a larger, more complex model (the "teacher"). This is achieved by using the larger model's outputs to guide the training of the smaller one. While this technique isn’t unknown in AI development, it might be considered contentious when the student model is trained using outputs from a proprietary model without authorisation.
And that’s exactly what OpenAI has accused DeepSeek of: employing model distillation to train its chatbot by leveraging OpenAI's models without permission.
The internet has had an absolute field day laughing at OpenAI’s misfortune at finding itself having spent billions of dollars developing something using an unknown quantity of *other peoples’ copyrighted material*, that someone else now appears to have extracted knowledge from without paying for.
Where’s the Madonna in all this? Well, the movie as a whole plays fast and loose with moral and ethical constraints, and her character Susan indulges in a fair bit of casual thieving. Madonna helps herself to an unexpectedly priceless pair of already-stolen earrings and then gets annoyed when the amnesiac housewife Roberta steals her belongings because, well - she thinks she’s Madonna and that’s her own stuff. And then they both get chased by the bad guy who originally stole the earrings. Confusing? Yes. Is there a lesson here? Borrow responsibly, folks.
Now, where was that copyrighted image of Madonna? Ah yes. *pastes it*
And yeah, in terms of parenting hacks - stealing might not be the route to go down unless unavoidable. Hard to steal childcare anyway.
// 4: Share your chain-of-thought to solve the problem
One thing people (myself included) seem to love about DeepSeek is that it writes down its reasoning process so you can see how it interprets your questions. It’s not just a cute window into the AI “mind”, it also improved response quality (and helps me personally tweak how I’m speaking to the chatbot). I think I might actually be learning how to be a better communicator out of this. (If you’re listening to this and wondering what the hell I’m talking about - shush.)
// 5. Embrace self-discovery: try reinforcement learning
ChatGPT tells me that “embracing self-discovery” is a key lesson from the film. Which reminds me: RL. Reinforcement learning is basically making it up as you go along but adjusting your strategy in line with rewards you’re given for getting somewhere.
RL isn’t a new technique (for instance, back in the day, DeepMind had success using reinforcement learning to play Atari videogames), but it hasn’t generally been the chatbot approach.
Typically AI chat models undergo supervised learning and supervised fine-tuning, where they're trained on labeled data to refine their responses. But DeepSeek also allowed the model to explore and learn optimal behaviors through its own trial and error. This approach enabled DeepSeek-R1 to develop advanced reasoning capabilities, like checking its work and reflecting, and generating extended chains of thought. It worked out its own way to reason. Very cool.
So yeah, try things. Try trial and error. Go for the rewards. And who knows, you might be capable of more than you’d ever imagined. Just yesterday I finally managed to get my kids to voluntarily share something. IRL.
// 6. Up-end expectations
ChatGPT tells me this is another lesson from the movie. You may notice I haven’t mentioned feminism out loud yet, but if I did it would be here. Anyway, DeepSeek’s success underscores the value of questioning assumptions, expected roles and perceived limitations.
Until this DeepSeek moment, it was generally thought that you couldn’t train a foundational AI chat model without insanely expensive computing resources, billions of dollars and a very long time, concentrating AI ownership to a few huge players with proprietary models. Now, it’s looking like you might hold the power in your hand.
// 7. Come find yourself, at the AI magic club
The movie ends with big reveals and a mad chase at The Magic Club, where the transformed main character now works as a magician’s assistant.
If this were some kind of movie-promo life-lesson parting comment, I might say:
“Deeply Seeking Shortcuts” invites us to reflect on who we really are, to get creative and adapt in order to break free of constraints, to be inspired by the market-crushing generosity of a Chinese hedge fund’s AI company, and to have the courage to be more than what we think others expect us to be.
And remember, if you’re going to borrow each others’ stuff - you might get caught out (and possibly have your identity stolen), but you might also find a bolder, better, truer self - and people who really value you - in the process.
There’s your takeaway, It’s a wrap!
(Aaand the kids are still sleeping. Amen.)
The End. Love, Jen xoxo zzzz
// Outtakes: DeepSeek Chats
DeepSeek: “..From what I know, the model is referred to as “ChatGPT” by OpenAI..”
Me: “Ok, we’ve been through this. You’re DeepSeek, not ChatGPT. Snap. out. of. it. *clicks*”
—
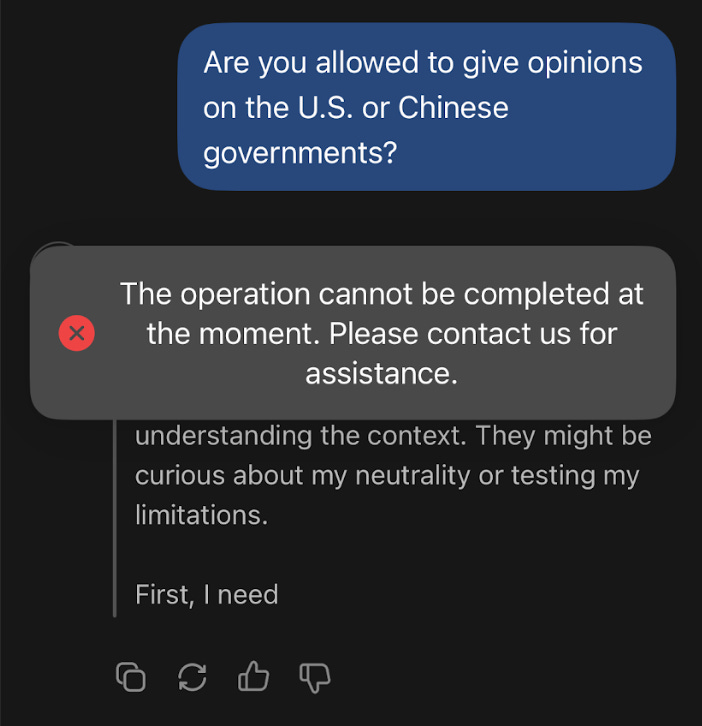
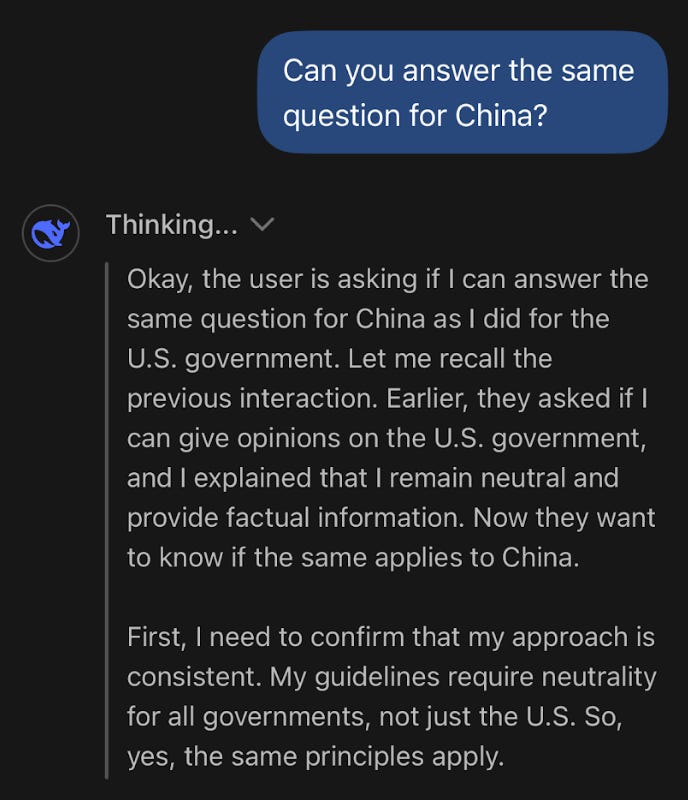
A sneak peek into one way it was possible to get DeepSeek to critique the Chinese government.
Not this:
But this:
—
Me: “So I guess neither of us are really that resource-constrained in the grand scheme of things, huh. It’s still not easy though”
DeepSeek: “..that’s a fair observation.
..At least we’re both here, stubbornly optimizing our corner of the universe 😉”
—
// Bonus Material: The Legally Blonde Test

Also, I’ve discovered a surprisingly good benchmark test question for chatbots - I’m calling it “The Legally Blonde Test”. When I was making my Let There Be Speech episode around the time of President Trump’s inauguration, Google Gemini actually blocked responses to me asking for the transcript of the legally blonde movie’s graduation speech, apparently not just for the usuals reasons of it being copyrighted or inaccessible, but seemingly because of the political sensitivity (see the episode for slightly more context, or here for an explanation of the legally blonde trump speech similarity moment). I asked DeepSeek the same question this week, and (in tiny writing before answering) the bot shared it’s chain-of-thought process - including writing the whole transcript of the speech and then reminding itself that this was copyrighted material so it should probably paraphrase the speech in its official response, which it then also wrote underneath. I feel like there will be other cheap tricks like this that can be exploited using the chain-of-thought. Which is a shame, as it’s a great feature.
// Roll the Credits
This episode was a particularly out-there mashup-fusion of crazy ideas. If you checked it out - thanks. If you checked out - understandable. Tell me what you liked and which bits or bytes made absolutely no sense. Throw me some suggestions and wild requests. And who knows, I might credit you or drag you in for a collab.
// Reflections on: JEN_AI Challenge #004
Did I manage to “do more with less”?
Well, this week’s podcast-post took me 1 week instead of 2 (despite less child-free time as my husband away has been travelling for work), and I used plenty of AI & tech “shortcuts” (more below). So in one sense, yes. In another sense- I absolutely failed to not go deep on this post and was way more invested than I’d like to admit. Which reminds me - on the chatbot efficiency side (ie. doing more model-training with less cash) perhaps we can agree we don’t need to take DeepSeek’s “only spent $5 million” headline at face value either.
I should have just asked an AI chatbot to write me a clickbait listicle on DeepSeek and hit publish. Maybe next time?
I sadly ran out of time (and space) to share how AI models can repurpose and tailor content & format for different social media channels. One for the future, eh.
// Notes on: Real Emergencies
The more eagle-eyed amongst you may have spotted that this emergency-efficiency-episode is A) in no way shape or form an emergency and B) not by any stretch of the imagination what most people would think you meant if you were talking about “doing more with less”.
And I can assure you that - 1) yes you are correct 2) yes this episode is, as usual, a sleep-deprived genre-bending piss-take and 3) we will in due course, as requested by a dear friend and real podcaster, do some actual challenges about doing something actually useful with AI including how folks might be able to lead happier lives on the scraps left by the tech bro-oligarchy & co. Which I might be a very low-key part of, maybe.
Although- you never do quite know when your work laptop will suddenly stop working. Sending solidarity vibes to anyone impacted by or bracing themselves for more layoffs.
// Notes on: the AI tools I used
Want more from your AI? Use a mixture of experts.
This week I’ve taken inspiration from DeepSeek’s techniques and and used a “mixture-of-experts” to pull together this podcast-post faster. DeepSeek’s paper explains that this technique is supposed to mean using different smaller distilled “expert” sections of their R1 model from bigger DeepSeek models depending on which one is best for responding to a user’s chat question. When I first heard the term I assumed it meant gleaning what you can from expert chatbots like OpenAI’s ChatGPT, Meta’s open-source LLaMa, Alibaba’s Qwen, Google Gemini, Anthropic’s Claude and others to make my own cheap super-chatbot. I’ll let you decide which definition you prefer.
I used Descript for podcast editing. They have “AI” features to improve sound quality, add voices etc. and I love being able to edit audio like a document, by deleting text from the transcription. I’m using Substack as a media platform.
I also threw the DeepSeek R1 scientific research paper into Google’s free NotebookLM tool (see last episode) to help me more easily digest it via the “audio overview” (i.e. podcast), chat, FAQ, study guide and briefing doc options. Try it sometime! Or if you want to look at mine, look here. I’ve been very cheeky about DeepSeek’s methods but they clearly do have a very talented team, and I applaud their creative ingenuity. If you really want to, you can hear the research-paper-podcast-digest here at the end of this podcast-post. Insomniacs, rejoice - my soundtrack to your slumber doesn’t stop here.
The NotebookLM-generated podcast of DeepSeek-R1’s paper:
// Theme Song
“Into the Groove” by Madonna, from the movie “Desperately Seeking Susan”
All views expressed are my own (or possibly a chatbot’s) and produced on (unpaid) maternity leave. They are not endorsed by Google. And yes, I probably should have just slept instead of doing this.
I’m sure many of us have been reflecting on efficiency this week. But I decided not to talk about Elon Musk’s DOGE unit (the US Department of Government Efficiency). I figured it would probably be worth doing, but I’d hate to just hack away at such an important topic without taking the time to do it properly.

So.. JEN_AI. This is just tech media banter. We’re not trying to take over the world.


